Hi there! My name is Teo Samaržija. I am a computer engineer (I have a
Bachelor degree in Computer Engineering from the FERIT school,
University of Osijek, graduated in 2023) born in 1999. I also have got a
front-end development certificate from the school called Algebra in
2025. Apart from computer engineering, I am also interested in
linguistics.
My software projects
I am primarily interested in front-end development (I've made
a blog-post about the CSS tricks I've found and consider
important), but I am also interested in low-level development and compiler
development. Previously, I was interested in competitive
programming. For example, I won
the 4th place on Infokup in 2013. However, now I think that the skills you learn at algorithmic
competitions are not very useful for developing large programs, if
they aren't even counter-productive.
The AEC programming language
At the end of the high-school, I came up with the idea of making a
programming language called Arithmetic Expression Compiler, or AEC
for short. I started by making
a web-app that converts arithmetic expressions to i486-compatible
assembly
(something similar to GodBolt Compiler Explorer, but with much fewer
features, and running in the front-end instead of on the back-end).
Then I made a rather-unprofessionally-made compiler that compiles my
programming language to assembly (using the Duktape framework, doing
high-level things in JavaScript and low-level things in C), and I
made a few small programs in AEC. Then I decided that I want to be
able to program in my programming language for the web, so I made a
AEC-to-WebAssembly compiler
from scratch. I rewrote it in C++ (rather than using JavaScript and
C, as my original AEC compiler does), and it is 5'500 lines of code.
I made a few short programs in it:
The
Analog Clock. It was challenging to make because you are using trigonometry
to make an analog clock, but WebAssembly has no instructions for
calculating trigonometric functions (like x86 has
fsin and so on). I had to make those functions myself
using what we were taught in our calculus classes at the
university.
For those who are curious, here is how I implemented
sin and cos (If you enable JavaScript,
you will see it syntax-highlighted.):
Function cos(Decimal32 degrees)
Which Returns Decimal32 Is Declared; // Because "sin" and "cos" are
// circularly dependent on one another.
Decimal32 sineMemoisation[91];
Function sin(Decimal32 degrees) Which Returns Decimal32 Does {
If(degrees < 0) Then { Return - sin(-degrees); }
EndIf;
If degrees > 90 Then { Return cos(degrees - 90); }
EndIf;
If not(sineMemoisation[asm_f32("(f32.nearest (f32.load %degrees))")] = 0)
Then { // I've used inline assembly here because nothing else I
// write will output "f32.nearest" (called "round" in most
// programming languages) WebAssembly directive, and it's way
// more convenient to insert some inline assembly than to modify
// and recompile the compiler.
Return sineMemoisation[asm_f32("(f32.nearest (f32.load %degrees))")];
}
EndIf;
/*
* Sine and cosine are defined in Mathematics 2 (I guess it's called Calculus
* 2 in the English-speaking world) using the system of equations (Cauchy
* system):
*
* sin(0)=0
* cos(0)=1
* sin'(x)=cos(x)
* cos'(x)=-sin(x)
* ---------------
*
* Let's translate that as literally as possible to the programming
* language.
*/
Decimal32 radians : = degrees / oneRadianInDegrees, tmpsin : = 0,
tmpcos : = 1, epsilon : = radians / PRECISION, i : = 0;
While((epsilon > 0 and i < radians) or (epsilon < 0 and i > radians)) Loop {
tmpsin += epsilon * tmpcos;
tmpcos -= epsilon * tmpsin;
i += epsilon;
}
EndWhile;
Return sineMemoisation[asm_f32("(f32.nearest (f32.load %degrees))")]
: = tmpsin;
}
EndFunction;
Function cos(Decimal32 degrees) Which Returns Decimal32 Does {
Return sin(90 - degrees); // Again, basic common sense to somebody who
// understands what those terms means.
}
EndFunction;
One of the interesting things about computer engineering is that,
to a layman,
this analog clock in JavaScript I made when I was 17
seems a lot more impressive than this analog clock in AEC. In
reality, this analog clock in AEC is far more impressive.
The
Dragon Curve. It was challenging because I had to interface
SVG
with my programming language.
The
Huffman Coding in AEC. It was challenging because dealing with structure pointers
exposed a few bugs in the compiler which I had to fix in order to
continue working.
I think that programming in a programming language you've made is a
good idea because it avoids bugs that come from misunderstanding the
language you are using. In my experience, many difficult-to-trace
bugs in my programs were caused by me being unaware of some quirk of
JavaScript or C++. I've written about that
on my blog. WebAssembly is designed to be an exceptionally easy target for
compilers, so WebAssembly makes programming in a programming
language you have designed yourself easy, at least for front-end
development.
The AEC programming language has a syntax inspired by Ada and
Microsoft SmallBasic, and the semantics is similar to C, but with
two major exceptions: arrays and pointers are different data types,
and unaligned access is allowed. Unaligned access being allowed in
AEC means pointer arithmetic works very differently in C and AEC.
For example, you need to check manually whether a pointer that
points to an address within an array is actually pointing to an
element of that array, rather than to, for example, the second byte
of the structure. This is how you properly check whether a pointer
points to an actual element of the array of structures (excerpt from
Huffman Coding in AEC):
InstantiateStructure TreeNode treeNodes[64];
Integer16 isTreeNodeUsed[64];
Function isTreeNodeWithinBounds(
PointerToTreeNode treeNode) Which Returns Integer32 Does {
Return AddressOf(treeNodes[0]) <= treeNode <= AddressOf(treeNodes[64 - 1]) and
mod(treeNode - AddressOf(treeNodes[0]), SizeOf(TreeNode)) = 0;
}
EndFunction;
In C, you don't have to check whether the mod is 0.
Since AEC is targetting x86 and WebAssembly, rather than
architectures such as ARM, I believe I made a good choice by
enabling unaligned access. The code translates to assembly more
directly that way. When targetting x86 or WebAssembly using C, the
compiler is essentially lying to you about how the computer
architecture you are targetting works.
And about the syntax, I've made two decisions different from any
programming language I know: the semi-colon is optional only after
EndIf, EndWhile and similar keywords (I've
made
a StackExchange question about that decision), and you can add optional curly braces after Then,
Else, Loop, and so on, and before
Else, EndIf, EndWhile, and so
on (to make it possible to use ClangFormat and similar tools for
C-like languages with my programming language).
One anecdote that made me think about just how counter-productive
the knowledge you gain at algorithmic competitions is this. I
wanted to build into my AEC-to-WebAssembly compiler suggestions for
the misspelt variable names. And, while preparing for algorithmic
competitions, I learned about the longest-common-subsequence
algorithm from dynamic programming (Rightly so, since there was
an LCS-related task called "More Keys"
on the
STEM Games 2019 competition
which I helped my team solve.). So, I supposed that algorithm might
be useful in my compiler. So I spent hours implementing the
longest-common-subsequence algorithm into my compiler to show
suggestions for mispelt variable names. And it didn't give good
results. Then I requested help on a Discord server about programming
languages, and somebody explained to me that the LCS algorithm is
not a good algorithm to use there, but that I should use Levenshtain
Distance. And I did, and then it gave me good results. That made me
think that algorithmic competitions encourage students to
superficially learn as many algorithms as possible without even
fully understanding what those algorithms are doing, which is
knowledge that is counter-productive in real-world programming.
A meme I made about competitive programming. You don't know the
basics of design, you don't know the quirks of the programming
languages that are widely-used due to technical reasons rather
than because of being good (such as JavaScript and PHP), and even
what you are supposed to be good at (data structures and
algorithms, as well as the programming language you were using at
the competition) you suck at, because even they aren't being
taught the right way.
I am currently writing an article about programming competitions and
how to improve them to teach more useful stuff.
It was the year 2020, the year of the plague. And my Computer
Architecture professor was afraid that the physical laboratory
exercises from Computer Architecture would be canceled. At our
Computer Architecture classes, we are using
Xilinx PicoBlaze
as an example of a simple computer. My professor was afraid that
students would, if physical laboratory exercises are cancelled, run
into all kinds of technical problems trying to run existing
PicoBlaze assemblers and emulators on the computers they have at
home. So, he tasked me to create a PicoBlaze assembler and emulator
which can be run in any modern browser. So I did. You can see
our work on SourceForge. I say "our" because now I am not the only
contributor to that project. My work
began being used at a university in Argentina, from which I got a contributor called Agustín Izaguirre. And then
a back-end developer from Turkey called Abidin Durdu also joined. It
is around 4'000 lines of code.
The assembler is rather unconventionally made. Apart from running in
a browser, its architecture is unconventional. Parsers of most
assemblers produce a matrix (a 2-dimensional array) of many small
trees, where each row in the matrix represents a row in the assembly
code, the first column containing labels, the second column
containing mnemonics, and so on. In that matrix, most of the trees
contain a single node, and only arithmetic expressions are encoded
using larger trees. I think that's a fundamentally wrong way of
structuring an assembler, and that it is the reason it's hard to add
new features to assemblers. The parser of my PicoBlaze assembler
works like a parser for a high-level language: it produces one large
syntax tree. It is probably the most feature-rich assembler for
PicoBlaze out there: it supports arithmetic expressions in the
constants (including the ternary conditional operator
?:, which assemblers in general tend not to support),
it supports if-branching, if-else branching, and while-loops in the
preprocessor, all while trying to stay compatible with the Xilinx'es
official assembler for PicoBlaze. Trying to stay compatible with the
Xilinx'es official assembler for PicoBlaze costs me a lot of
freedom. For instance, I don't like the fact that numerical
constants are hexadecimal by default. I would like them to be
decimal by default. But if I do that, well, I'll break
compatibility.
On 01/02/2025, I decided I will make a compromise: I've added
preprocessor directives base_decimal and
base_hexadecimal that change how numerical literals
without an explicitly specified base are being handled. The
default is still to interpret them as hexadecimal, but if you
insert the directive base_decimal, the assembler will
interpret all the numbers without a specified base that come after
that directive as decimal. Similarly, if you insert the directive
base_hexadecimal, it will interpret them as
hexadecimal. It reminds a bit of the GNU Assembler allowing you to
mix Intel Syntax and AT&T Syntax in the same assembly language
file, but it's less extreme.
Though, to be honest, I am not really sure how useful those
assembler features are when writing real-world applications. In my
Binary to Decimal program, I never used them. In
Decimal to Binary, I only used arithmetic expressions once,
to deal with ASCII:
;Check whether the character is a digit.compares9,"0";If it is not a digit, jump to the
;part of the program for printing
;the number you have got.jumpc, print_the_number
compares9,"9"+1;Comparing with "9" + 1 instead of "9"
;in order to reduce the number of
;instructions is a suggestion by a
;StackExchange user called Sep Roland.jumpnc, print_the_number
The "9" + 1 is an arithmetic expression, something that
the Xilinx'es official assembler doesn't support. And this can be
done without the arithmetic expressions in constants, it's only that
they allow reducing the number of instructions while keeping the
code legible. So, yeah, maybe my assembler is trying to do too much.
It would be interesting to make an empirical study by dividing the
Computer Architecture students into two groups, one group using
Notepad++ (Ivana Vučić from FERIT made a language server for PicoBlaze
assembly language that facilitates editing PicoBlaze assembly
language in Notepad++) and Xilinx'es official assembler, and the other group using my
PicoBlaze assembler and emulator, and see which of those two groups
will fail laboratory exercises at a higher rate. And asking those
students what annoyed them the most from the tools they used (I, for
example, find having to put traling zeroes in hexadecimal constants
to make my program assemble using the Xilinx'es assembler very
annoying. And I also find
the fact that syntax highlighting in my PicoBlaze assembler and
emulator is not entirely correct
annoying as well.). That would give me a good feedback on whether my
work is actually useful when there is no pandemic. Anecdotal
evidence is contradictory. Agustín Izaguirre says that my work is
being used at a college in Argentina "to a great effect", but students from FERIT whom I asked about that hadn't used
my work at all.
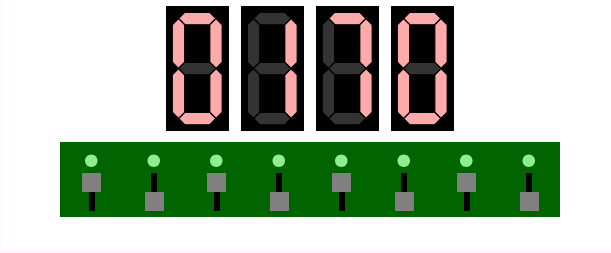
An example execution of the Binary to Decimal example
program. The user entered, using the switches, the binary number
10101010, which the program converted to decimal
170 and to
Gray Code11111111 (shown using LEDs).
That project was my Bachelor thesis. One of the challenges I faced
is how do I present it as my Bachelor thesis considering that I am
not the only author of it. You can read more about that problem
on StackExchange. I also often ask myself why are universities teaching Computer
Architecture using obscure CPUs such as PicoBlaze, rather than using
x86 or ARM. If my university used x86 or ARM to teach Computer
Architecture, the situation because of which I had to make that
PicoBlaze assembler and emulator couldn't have happened. I asked
that question as well on StackExchange.
Now, about projects similar to my PicoBlaze assembler and
emulator... Well, a FER student called Ivan Žužak made
an assembler and emulator for FRISC in JavaScript. However, I guess it's not for similar reasons: he made that years
before the pandemic.
And thinking about why I made that PicoBlaze assembler and emulator
runnable in a browser made me realize just how accurate the Ayn
Rand's notion about engineering is. Ayn Rand is one of the most
prominent philosophers of modern libertarianism (the form of
libertarianism known as objectivism), and she said that, while there
are some technological advancements that make our lives better
(medical technologies...), most of the so-called technological
advancements are solving problems that the technologies we became
dependent on created. Most of the technological advancements are
solving problems which don't exist in nature, but which the
technologies we became dependent on created. By the 1980s, we had
become dependent on computers and software. A little problem is: the
digital electronic circuits we are using aren't programmable. You
can have a very powerful CPU capable of running programs for x86
computers, but if you want to run programs for ARM CPUs on it...
Good luck with that. You can, at best, hope to have an emulator
which will enable you to run those programs, but at a much degraded
speed. That's why, in 1983, the engineers at Altera came up with
FPGAs. But FPGAs
were not very useful back then because, well, there was no
high-level programming language targetting them. That's why the
engineers working for the US government came up with
VHDL. But
they were still not very useful because, well, no actual CPU was
capable of being synthesized on FPGAs. This is especially important
since VHDL compilers cannot synthesize, for example, dividing a
number by something that's not a power of 2: to do stuff like that,
you need a CPU synthesized on the FPGA (You read that right!).
That's why the engineers at Xilinx came up with PicoBlaze, a
processor written in VHDL and entirely synthesizable on FPGAs. And
Xilinx also made an assembler for PicoBlaze. And, since you probably
want to have an emulator when you are developing for an exotic
computer architecture such as PicoBlaze (so that you can test the
programs on the computer you are developing them on, which is
probably either x86 or ARM, rather than PicoBlaze), there have been
multiple both open-source and non-open-source emulators for
PicoBlaze. But then, as the technology advanced (better say,
"changed without a good reason"), those assemblers
and emulators wouldn't run on many new computers. So I had to make
an assembler and an emulator for PicoBlaze again, this time in
JavaScript, in hope that it will remain runnable on various
computers for decades to come (as JavaScript cares about backwards
compatibility more than other mainstream languages do). And I
received validation that I am doing good work (Agustín Izaguirre and
Abidin Durdu joining me). But did I actually do good work? Or is the
right thing to do in this case to refuse to do anything about it,
because, as they say, "You cannot get out of a hole by digging."? You be the judge. But keep in mind that is what programmers
do! They mostly solve problems that the technologies we became
dependent on created, and they create new problems in the process.
PicoBlaze, along with creating the problem of assemblers and
emulators for it, also created an even bigger problems of C
compilers targetting it (because it is far from an easy compilation
target).
I do not think an average person realizes that. My father was, when
my mother was in jail, telling me: "Look, Teo, when you are a programmer, you won't be working on the
abstract idea of programming. You will not be programming Jesus
and Mary in the air. You will be programming physical devices. And
the physics and mathematics you will be taught at the university
will help you understand how those devices work.". Back then, that contention seemed plausible to me, but now
it does not. What are some problems you need to write a non-trivial
piece of software to solve? Making it possible to do laboratory
exercises with PicoBlaze during a pandemic? Well, you do not need
any physics or university-level mathematics for that. Programmers in
the business world are often tasked with converting some large Excel
document into an SQL database query. Again, you do not need to know
any physics or mathematics for that, you need to know frameworks and
libraries for that. Most of what programmers do is a lot better
described by "programming Jesus and Mary in the air" than by "programming physical devices you need to know mathematics and
physics to understand".
SVG PacMan
Back in high-school, as an attempt to learn JavaScript well, I made
a PacMan game which uses SVG. It is around 1'500 lines of code.
What the PacMan game looks like before it is started.
I have got a cross-site scripting attack on my SVG PacMan game quite
a few times (because I didn't sanitize the input properly because I
didn't know PHP), and that caused me to think that, when you make a
web-app, it is a good idea to make a front-end-only version of your
web-app so that at least some functionality of your web-app remains
available in case you get a cross-site scripting attack. That's why
I made
a front-end only version of my SVG PacMan
as well as
a front-end only version of my PicoBlaze assembler and
emulator.
Etymology Game
At the end of high-school, I came up with the idea to make a rather
original game: a flash-card game in which the goal is to guess
etymologies of the words in simulated languages. I decided to use
the JQuery framework for that. With a little help of a front-end
developer called Boris Muminović, I managed to. So you can now play
the
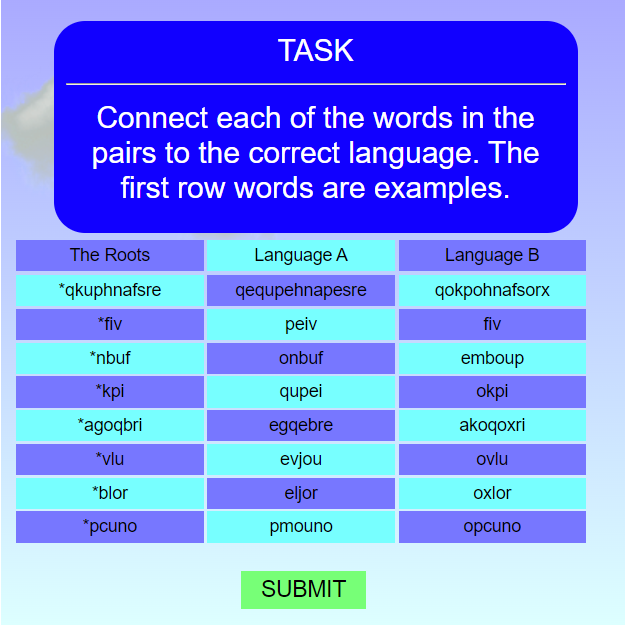
Etymology Game. It consists of three parts. In part one, you are supposed to
recognize which words from the two simulated languages are cognates.
In part two, you are supposed to guess to which of the two simulated
languages each word belongs (I got that idea from
the task Tocharian on International Linguistics Olympiad 2003). In part three, you are supposed to guess which set of sound
changes belongs to which language. It is around 2'500 lines of code.
Part one
Explanation of how to solve the part two using two related
languages Croatians are the most familiar with: English and
German
Part twoPart three
Of course, in order to do that, I needed to make a lot of guesses
about how languages really behave. So, when I was a third-year
Computer Engineering student, I decided to test my algorithms
against real-world data. For real-world data, I took the names of
the numbers one to ten in various languages (attested and
reconstructed). Unfortunately, the results weren't particularly
impressive: it did little better than chance. The algorithm used in
Etymology Game guessed the correct evolution of a word in a
real-world language
0.5602715172868801% of the time, whereas an algorithm which outputs random results (not even
caring about whether the result is pronounceable) guessed it
0.4797068286747768% of the time.
And that made me think how absurd it is for governments to think
they can control the language (make language more pure of
loan-words, revitalize endangered languages...). If we cannot
predict how languages will evolve much better than chance, what
makes us think we can know whether language policies produce
desired results? Don't you think we are much more likely to get an
illusion of control than to actually control the language?
What's amazing to me is that programmers say they want original
games and programs, but it seems that they don't really want that.
For example, my Etymology Game is arguably the most original thing
I've ever made, but it has 0 stars and forks on GitHub. Programmers
say they don't want another programming language or an assembler,
but it seems they actually want precisely that. The repository on
GitHub I made which has the most stars is my AEC-to-WebAssembly
compiler. And the one with most actual contributors is my PicoBlaze
assembler and emulator. It seems that the world really needs another
assembler.
A common misconception is that a computer model that predicts how
languages will, on average, change much better than chance would be
useful for historical linguistics. No, it would not be useful, it
would just be a curiosity. What would help historical linguistics
significantly would be a way to estimate the p-values of the
patterns in the names of places (more on that later).
My other work
Like I've said in the introduction, apart from computer engineering,
I am interested in linguistics. I am also interested in libertarian
politics and vegetarianism.
My linguistic theories
I have always been interested in classical languages.
In 2016, I won the 8th place on the AZOO competition in the
Latin language. You can read
my blog-post in which I explain the basic principles of
historical linguistics, I am as proud of it now as I was back in 2017 when I published
it. My hobby is publishing and discussing papers about the names
of places. In 2022, I published a paper called "Etimologija Karašica" in two peer-reviewed journals:
Valpovački Godišnjak
and Regionalne Studije (an almanac for the Croatian national
minority in Hungary, based in Sopron).
Now, I concede that whether my paper was really
peer-reviewed is a matter of debate. The reviewers in
question were dialectologists and other people from fields
distantly related to what I was writing about. They weren't
people educated in the interdisciplinary field that touches both
linguistics and information theory (such people are,
unfortunately, rare).
The paper, edited much differently from the version that was
published in those two journals (The editors of Valpovački
Godišnjak forced me to delete the discussion about whether
Illyrian was centum or satem, as it was, according to them,
irrelevant.), is available
on my blog. Here is the English-language summary of that paper:
To summarize, I think that I have thought of a way to measure the
collision entropy of different parts of the grammar, and that it
is possible to calculate the p-values of certain patterns in the
names of places using them. The entropy of the syntax can
obviously be measured by measuring the entropy of spell-checker
word list such as that of Aspell and subtracting from that an
entropy of a long text in the same language (I was measuring only
for the consonants, I was ignoring the vowels, because vowels were
not important for what I was trying to calculate). I got that, for
example, the entropy of the syntax of the Croatian language is
log2(14)-log2(13)=0.107 bits per symbol, that the entropy of the
syntax of the English language is log2(13)-log2(11)=0.241 bits per
symbol, and that the entropy of the syntax of the German language
is log2(15)-log2(12)=0.3219 bits per symbol. It was rather
surprising to me that the entropy of the syntax of the German
language is larger than the entropy of the syntax of the English
language, given that German syntax seems simpler (it uses
morphology more than the English language does, somewhat
simplifying the syntax), but you cannot argue with the hard data.
It looks as though the collision entropy of the syntax and the
complexity of the syntax of the same language are not strongly
correlated. The entropy of the phonotactics of a language can, I
guess, be measured by measuring the entropy of consonant pairs
(with or without a vowel inside them) in a spell-checker wordlist,
then measuring the entropy of single consonants in that same
wordlist, and then subtracting the former from the latter
multiplied by two. I measured that the entropy of phonotactics of
the Croatian language is 2*log2(14)-5.992=1.623 bits per consonant
pair. That 5.992 bits per consonant pair has been calculated using
some mathematically dubious method involving the Shannon Entropy
(As, back then, I didn't know that there is a simple way to
calculate the collision entropy as the negative binary logarithm
of the sum of the squares of relative frequencies of symbols, I
was measuring the collision entropy using the Monte Carlo method.
The Shannon entropy is 7.839 bits per consonant pair, and the
maximal possible entropy is log2(26*26) bits per consonant pair,
so I suppose the collision entropy is around 5.992 bits per
consonant pair.). Now, I have taken the entropy of the
phonotactics to be the lower bound of the entropy of the
phonology, that is the only entropy that matters in ancient
toponyms (entropy of the syntax and morphology do not matter then,
because the toponym is created in a foreign language). Given that
the Croatian language has 26 consonants, the upper bound of the
entropy of morphology, which does not matter when dealing with
ancient toponyms, can be estimated as
log2(26*26)-1.623-2*0.107-5.992=1.572 bits per pair of consonants.
So, to estimate the p-value of the pattern that many names of
rivers in Croatia begin with the consonants 'k' and 'r' (Karašica,
Krka, Korana, Krbavica, Krapina and Kravarščica), I have done some
birthday calculations, first setting the simulated entropy of
phonology to be 1.623 bits per consonant pair, and the second by
setting the simulated entropy of phonology to be 1.623+1.572=3.195
bits per consonant pair (In other words, in the second birthday
calculation, I assumed the entropy of morphology was 0). In both
of those birthday calculations, I assumed that there are 100
different river names in Croatia. The former birthday calculation
gave me the probability of that k-r-pattern occuring by chance to
be 1/300 and the latter gave me the probability 1/17. So the
p-value of that k-r-pattern is somewhere between 1/300 and 1/17.
Mainstream linguistics considers that k-r pattern in Croatian
river names to be a coincidence, but nobody before me (as far as I
know) has even attempted to calculate how much of a coincidence it
would have to be (the p-value). So I concluded that the simplest
explanation is that the river names Karašica, Krka, Korana,
Krbavica, Krapina and Kravarščica are related and all come from
the Indo-European root *kjers meaning horse (in Germanic
languages) or to run (in Celtic and Italic languages). I think the
Illyrian word for "flow" came from that root, and that the
Illyrian word for "flow" was *karr or *kurr, the vowel difference
'a' to 'u' perhaps being dialectical variation (compare the
attested Illyrian toponyms Mursa and Marsonia, the names Mursa and
Marsonia almost certainly come from the same root, but there is a
vowel difference 'a' to 'u' in them). Furthermore, based on the
historical phonology of the Croatian language and what's known
about the Illyrian language (for example, that there was a suffix
-issia, as in Certissia, the ancient name for Đakovo, but not the
suffix -ussia), I reconstructed the Illyrian name for Karašica as
either *Kurrurrissia (borrowed into Proto-Slavic as *Kъrъrьsьja,
which would give *Karrasja after the Havlik's Law, and then
*Karaša after the yotation and the loss of geminates, to which the
Croatian suffix -ica was added) or *Kurrirrissia (borrowed into
Proto-Slavic as *Kъrьrьsьja, which would also give *Karaša by
regular sound changes), and the Illyrian name for Krapina as
either *Karpona (borrowed into Proto-Slavic as *Korpyna, which
would give "Krapina" after the merger of *y and *i and the
metathesis of the liquids) or *Kurrippuppona (borrowed into
Proto-Slavic as *Kъrьpъpyna, which would also give "Krapina" by
regular sound changes), with preference to *Karpona. Do those
arguments sound compelling to you?
From my experience discussing my theory on various Internet
forums, I'd say there are two arguments against it which are not
completely insane (Most of the people advocating mainstream linguistics on
Internet forums seem to have blind faith that information theory
has nothing to say about toponyms, which is a view that's, in my
opinion, not only not right, but is also
not even wrong.):
Your experiment is flawed because it doesn't take into account
the possibility that nouns in the Croatian language have a
significantly lower collision entropy than the rest of the words
in the Aspell word-list. River names are nouns.
My response: If the Croatian language had a
Swahili-like grammar, that may be a proper response. In
Swahili, nouns can only start with one of 18 prefixes
(called noun classes), while verbs can start with
whatever the phonotactics allows. But Croatian grammar is
not remotely like that. What magic would make nouns have a
significantly lower collision entropy than verbs in the
Croatian language? I think that your fallacy is ad-hoc
hypothesis.
Proto-Slavic phonotactics didn't allow four syllables with yers
to be consecutive, like in your supposed Proto-Slavic form of
the river name "Karašica", *Kъrъrьsьja.
My response: Do you have any source for
that claim? Also, the mainstream onomastics seems to be fine
with proposing etymologies which involve four consecutive
yers in Proto-Slavic forms. For instance, mainstream
linguistics claims that the town name Cavtat comes
from Latin (in) civitate, and the Proto-Slavic form
therefore must have been *Kьvьtъtь.
Since the 'a' in civitate was long in Classical
Latin, it would regularly be borrowed as Proto-Slavic
*a, rather than back yer. The Proto-Slavic form was
*Kьvьtatь.
My resonse: That's not at all how
Vulgar Latin phonology worked. One of the basic
facts about Vulgar Latin phonology is that Vulgar
Latin didn't make a difference between short and
long 'a'. See
this NativLang video
for more information about Vulgar Latin phonology.
(The conversation devolves completely...)
After nearly three years of debating that argument on Internet
forums, I received a rather interesting response: that I am
significantly underestimating the entropy of phonotactics
because of not taking into account the Law of Sonority. That I
am assuming that consonant pairs that occur in the beginnings of
words are strongly positively correlated with consonant pairs
that occur in the middle or the end of a word, and that that's
not true, and that it is especially not true for languages with
many consonant clusters allowed in beginning or end of word
(because the Law of Sonority says that consonant clusters which
are common at the beginning of words are rare at the end of
words). This response deserves
a whole paper dedicated to it.
Overall, I am relatively confident that my theory is correct,
among other things because plenty of people I know in real life
who know something about information theory have read my paper and
say that my arguments sound compelling to them. Now, admittedly,
regarding my idea that Karašica was called *Kurrurrissia in
antiquity, the problem is that the early historical phonology of
Croatian tends not to be well-known, even among
linguistically-educated people, and it's the early historical
phonology of Croatian that's necessary to evaluate my linguistic
claims. In my experience, even linguistically educated people tend
not to know that in early Proto-Slavic (that Croatians were
speaking in the 7th century and that the toponyms were borrowed
into), before the yers were schwa-like sounds, front yer is
reconstructed to have been pronounced as short 'i' and back yer as
short 'u'. So you can perhaps dismiss the fact that
linguistically-educated people I know in real life say my
arguments seem compelling to them as not meaning much. You might
even say that the educated guesses about how Croatian was
pronounced between the 7th and the 11th century (when it was not
attested) are too speculative to be considered science. But I
think that we can be rather confident that basic information
theory does indeed strongly suggest (it doesn't prove, since you
can make ad-hoc hypotheses such as asserting that nouns somehow
magically have a significantly lower collision entropy than other
words in the Aspell word-list) that the probability of that k-r
pattern occurring by chance is somewhere between 1/300 and 1/17.
And, related to that, I advocate the theory that Illyrian belonged
to the centum branch of the Indo-European languages. Most Croatian
linguists, ever since the 1930s, think it belonged to the satem
branch of Indo-European languages. I'll share
what I posted on r/latin (Reddit subreddit about Latin
language) about that, just to get a general idea:
Eratne lingua Illyrica "centum" aut "satem" lingua? Suntne
Albani nativi in Balkane?
Quid homines in hac agora censent, eratne lingua Illyrica "centum"
aut "satem" lingua? Linguae Indo-Europeae omnes in duas uniones
divisae sunt: "centum" et "satem". In "centum" linguis,
Indo-Europeanum phonemum 'kj' in 'k' vertitur. Lingua Latina est
"centum" lingua, etiam sunt lingua Graeca et lingua Anglica. In
lingua Anglica vere 'kj' in 'h' vertitur, sed, quodam tempore,
ante Grimmi legem, 'kj' in 'k' vertebatur in lingua Anglica, et
propterea lingua Anglica est "centum" lingua. In "satem" linguis,
'kj' in 's' vertitur. Exempla "satem" linguarum sunt lingua
Croatica, lingua Albanica et lingua Sanskrit. James Patrick
Mallory scripsit in Encyclopedia of Indo-European Culture se
censere id, num Illyrica erat "centum" aut "satem", ex datis quae
habemus, sciri non posse. Plurimi linguistae in Croatia, et alibi
in Balkane, censent linguam Illyricam fuisse "satem" linguam et
etiam progenitorem esse linguae Albanicae. Sed ego censeo linguam
Illyricam "centum" linguam fuisse. Die ante heri, ego publicavi
YouTube filamentum in lingua Croatica de eo.
https://youtu.be/4QQ2iJZnyUk
In eo filamento, do quinque argumenta pro idea quia lingua
Illyrica erat "centum" lingua. Ea argumenta sunt:
'K'-'r' regularitas in nominibus fluminum in Croatia. In
multis nominibus fluminum in Croatia, primus consonans est 'k'
et secundus consonans est 'r': Krka, Korana, Krapina,
Krbavica, Kravarščica, et duo flumina cum nomine
Karašica. Plurimi linguistae censent eam regularitatem
coincidentalem esse, sed ego censeo quia theoria informationis
(Paradoxa Dierum Natalium et Entropia Collisionum) docet nobis
quia probabilitas ut ea regularitas apparet coincidentaliter
est inter 1/300 et 1/17. Calculationem habetis in meo textu
"Etimologija Karašica", quod publicavi in almanaco
Valpovački Godišnjak anno Domini 2022-o. Ego censeo quia nomen
"Karašica" venit ex Illyrico nomine Kurr-urr-issia, et
quia "kurr" significabat "fluere" (probabiliter ex
Indo-Europea *kjers, quod significabat "currere"), "urr"
significabat "aqua" (ex Indo-Europea *weh1r), et "-issia" erat
suffixum in lingua Illyrica, quod etiam est in antiquo nomine
pro Đakovo, "Certissia". Per me, nomen "Kurrurrissia"
ivit ex Illyrico in Prae-Sclavicum
*Kъrъrьsьja, quod dedit
"Karrasj-">"Karaš-ica" (-ica est Croaticum suffixum)
in hodierna lingua Croatica. Ego etiam censeo Krapina venisse
ex Illyrico nomine Kar-p-ona, "kar" ex *kjers, "p" ex *h2ep
(aqua), et "ona" erat suffixum in multis Illyricis nominibus
locorum, inter alia, "Salona" et "Albona". Per me, nomen
"Karpona" ivit ex Illyrico in Prae-Sclavicum *Korpyna, quod
dedit "Krapina" in hodierna lingua Croatica. Et cetera...
Si lingua Illyrica erat "centum" lingua, "Curicum", antiquum
nomen pro Krk, potest legi ut "caurus, ventus borealis", ex
Indo-Euroepea *(s)kjeh1weros (unde Latinum verbum "caurus"
venit), et Krk est borealissima insula in mare nostro.
Si lingua Illyrica erat "centum" lingua, "Incerum", antiquum
nomen pro Požega, potest legi ut "cor vallis", ex
Indo-Europeais radicibus *h1eyn (vallis) et *kjer(d) (cor).
Si lingua Illyrica erat "centum" lingua, "Cibelae", antiquum
nomen pro Vinkovci, potest legi ut "firma casa" vel "castrum",
ex Indo-Europeis radicibus *kjey (casa) et *bel (firmus).
Multae inscriptiones in lingua Illyrica incipiunt cum "klauhi
zis", et id probabiliter significabat "Audiat Deus...".
"Klauhi" ergo probabiliter venit ex *kjlew (audire), ergo, *kj
vertitur in *k in lingua Illyrica.
Audiunturne ea argumenta vobis compellentia?
In case you want to watch the YouTube video I made, but your
browser cannot stream MP4 videos, try downloading
this MP4 file
and opening it in VLC Media Player or something similar.
To make something clear, I don't think that most of the
etymologies I suggested in the Latin text above are right. I just
think that together (not in isolation) they make
a strong case that Illyrian was a centum language.
If you would like to read a rather long paragraph about what I
think mainstream linguistics gets very wrong when dealing with
names of places (and, consequently, languages which are primarily
attested through names of places, such as Illyrian), enable
JavaScript and
click here.
Here is what I think mainstream onomastics (the part of
linguistics that deals with names) gets wrong. One of the basic
principles of mainstream onomastics is that the etymologies from
languages we know well (Croatian, Latin, Celtic...) are preferred
over the etymologies from languages we know little about
(Illyrian...). Well, I think that principle is wrong for two
reasons. The first reason is: What is the mathematical foundation
which suggests that the etymologies from languages we know well
are more probable than etymologies from languages we know little
about? It seems to me there is no mathematical basis for that
assumption. The second reason is that the principle seems
incompatible with information theory. The mainstream methodology
gave the result that this k-r pattern in the Croatian river names
is a coincidence, but basic information theory strongly suggests
that the pattern is statistically significant (that its p-value is
somewhere between 1/300 and 1/17). The right thing to do is to
throw away that methodology and search for a better one, and
revise everything that the old methodology produced using that new
methodology (For similar reasons, I think that economic "schools of thought" that are difficult to make compatible with basic game
theory should be rejected.). Maybe my methodology isn't good,
after all, it's pretty ad-hoc. But at least it's not blatantly
incompatible with information theory, like the mainstream
methodology is. There are a few other problems with mainstream
onomastics, but I think the adherence to that questionable
principle is by far the biggest one. Let me be clear that I am not
saying that the comparative method of reconstructing
proto-languages is wrong. Comparative method is based on good
principles: systematic sound-changes is indeed how languages
behave, and it's indeed mathematically improbable that two
unrelated languages would show apparent regular sound
correspondences. But what the linguists are doing when studying
toponyms has almost nothing to do with the comparative method. I
am not even saying that all the etymologies that the
mainstream onomastics gave are wrong. Some Illyrian etymologies
will appear probable no matter which methodology you are using.
For instance, that Serapia (the ancient name for the Bednja river)
is a compound word of *ser (to flow) and *h2ep (water) and that -ia is a common suffix in Illyrian
(Marsonia, Pannonia, Andautonia...), so that
Serapia literally means "flowing water". Such
extremely transparent names of places are rare, though.
I think that most of the people who study names of places know
almost nothing about the information theory, so they cannot
realize that their methodology flies in the face of it.
Furthermore, I think that many people who do know something about
information theory misinterpret the Birthday Paradox as if it is
saying that the probability of patterns such as the k-r pattern in
the Croatian river names occurring by chance is high. If the
Birthday Paradox actually said such a thing, then the mainstream
methodology of onomastics would probably be justified. But the
Birthday Paradox actually says no such thing, the Birthday Paradox
basically disappears once the number of people who share the same
birthday increases to three or four. However, probably the easiest
way to realize that fact about the Birthday Paradox is to do
numerical calculations, and, unfortunately, people who study names
of places tend not to know basics of programming. And then perhaps
many people who do realize those things rationalize that a
statistical model which is callibrated against real-world
linguistic data would suggest that the k-r pattern is not actually
statistically significant (In other words, that, even though
information theory and mainstream onomastics are deeply
incompatible in theory, perhaps they are compatible in practice.).
To really evaluate that claim, one probably needs to have a rather
deep understanding of the basics of the information theory (to
realize what Collision Entropy is and why it is relevant here) and
also know at least basic programming (to statistically analyze an
Aspell word-list and a long text in the Croatian language), and
most of the onomasticians understand neither of those things. It's
easy to see why somebody who is indoctrinated into mainstream
onomastics would have a rather difficult time escaping it. And
when you put a lot of effort and show them a paper that explains
clearly how they have been fooled (how basic information theory
strongly suggests the p-value of that k-r pattern is somewhere
between 1/300 and 1/17), the proponents of mainstream onomastics
don't want to admit that. They will make blatant ad-hoc hypotheses
("What if the collision entropy of the nouns in the Croatian
language is significantly lower than the collision entropy of
all of the words in the Aspell word-list?" or "Maybe if you calculate only with river names that have no
obvious Slavic roots, you will get a significantly higher
p-value."), or make wild empirical claims without evidence to
contradict my theories ("Proto-Slavic phonotactics didn't allow four consecutive
syllables with yers." or "River names and stream names that start with k-r are about as
common in Serbia as they are in Croatia, and Illyrian wasn't
spoken in Serbia. In ancient times, in Serbia, Dacian and
Thracian were spoken, and (unlike for Illyrian which is so
poorly attested that we do not know whether it was centum or
satem) we can be sure they were satem languages. Those river
names in Serbia cannot come from *kjers, so I see no reason to assume those river names in Croatia
do."), or pretend not to be able to understand my calculations
("What is a logarithm? Why am I supposed to know that?"), or use some unarticulated arguments ("Attempting to apply information theory to toponyms is not an
advancement in methodology, it is a methodological error,
because [some unintelligible word-salad]." or "Are you implying that the words 'krava' (cow) and 'karfiol'
(cauliflower) come from that supposed Illyrian word meaning 'to
flow'?"). It's very frustrating.
Makes me wonder, why should people who advocate mainstream
onomastics be treated any better than the typical Moon Landing
conspiracy theorists? When I was a Moon Landing conspiracy
theorist in 2016, somebody said about me: "Had he actually done the math and found that, for example, a
rocket launched from the Earth for some reason cannot reach the
Second Cosmic Speed, that would be different. But what he is
doing now is incredibly insulting.". Yeah, if people advocating mainstream onomastics actually
made a statistical model of a language which suggests that the k-r
pattern is not actually statistically significant (for example, by
actually compiling a long list of nouns in the Croatian language
and measuring the collision entropy of the nouns, showing that
they really have lower collision entropy than the rest of the
words in the Aspell word-list), or perhaps if they presented a
mathematical explanation of why etymologies from languages we know
well are more probable than etymologies from languages we know
little about (so that we can perhaps determine the real p-value,
the p-value adjusted for how much we know about some ancient
languages, using the Bayesian Theorem), that would be different.
But what they are doing now can rightfully be considered
insulting.
Another reason, which I think demonstrates how absurd mainstream
onomastics is, is the fact that the proponents of mainstream
onomastics aren't nearly as skeptical towards the patterns in the
toponyms which support their narrative. They, for example, will be
happy to point you to the fact that d-n in river names repeats in
places where Scythian was spoken in antiquity (Danube, Don,
Dniester, Dnieper...), as evidence that *danu was the Scythian
word for "to flow". Does that supposed pattern
hold up to scrutiny? If I had to guess, I would say no, that the
d-n pattern is probably not statistically significant. At best,
you can put it in the same category as the k-r pattern in the
Croatian river names. So why aren't the proponents of mainstream
linguistics just as skeptical of that d-n pattern as they are of
the k-r pattern? Proponents of mainstream linguistics, in my
experience, generally respond to that argument by claiming that
the d-n pattern is statistically significant because words
starting on dn- are rare in Slavic languages, while words starting
on kr- are common. But it's difficult to see how that response
could work mathematically. It seems to me (and to the experts in
information theory who reviewed my paper) that the only thing that
matters about the language spoken in the area when calculating the
p-values of such patterns in the toponyms is the collision
entropy, that it doesn't matter how common individual pairs of
consonants are. At least with the objection "Perhaps nouns have a significantly lower collision entropy than
the rest of the words in the Aspell word-list." it's obvious how it could work mathematically, but it's
not at all obvious how the objection "K-r is common in native Slavic words, while d-n isn't." could work mathematically. It seems to be simply a
misunderstanding of the information theory.
Previously, I was advocating the theory that Proto-Indo-European
and Proto-Austronesian are related (in particular, that
Proto-Indo-European *s regularly corresponds to Proto-Austronesian
*q, that Proto-Indo-European *r regularly corresponds to
Proto-Austronesian *l, and that Proto-Indo-European *d regularly
corresponds to Proto-Austronesian *d), but now I think that
advocating such theories is a hopeless waste of time. I think my
time is much better spent attempting to determine some things
about Illyrian than to attempt to determine deep-time language
relationships. Attempts to determine deep-time language
relationships have been done ad nauseam, but attempting to
apply information theory to the Croatian toponyms seems like a
low-hanging fruit. When you are on an Internet forum, don't use
arguments that have been tried ad nauseam, because that
will be read as "I want to be the person who discovered something new, but I
don't want to put a lot of effort into that.".
I calculated that the probability of such a pattern as
Proto-Indo-European *s corresponding to Proto-Austronesian *q
occurring by chance is around 6%, but now I am quite sure that the
linguistic assumptions that calculation is making are highly
unrealistic (for instance, it is making the assumption that the
collision entropy of a single consonant in both proto-languages is
around log2(20)), and that a better calculation would give a much higher
p-value. In Proto-Indo-European, for many words (perhaps even most
words beginning with s-), we aren't sure whether they actually
began with an s- or whether that s- is actually a later
contamination in many daughter languages (that's called s-mobile),
which would drive the p-value even higher, more so than for modern
or well-attested languages.
One thing I think everybody, who has done some serious work
attempting to mathematically model a language, will agree on is
that making unrealistic linguistic assumptions can easily skew
your calculations by several orders of magnitude. Our intuition
will often tell us some effect from linguistics cannot have a
major effect on our calculations, but indeed it does. You need to
callibrate your computer models against real-world data. If you
assume that the collision entropy of the consonant pairs in the
Croatian language is around log2(20*20), the p-value of the k-r pattern in the Croatian river
names appears to be around 1/10'000. But if you try to actually
measure the collision entropy of different parts of the grammar of
the Croatian language, you will get a result that it is somewhere
between 1/300 and 1/17. That's a difference of almost 2 to almost
3 orders of magnitude.
Similarly, it's important to understand the basics of information
theory, so that you don't use Shannon entropy where the collision
entropy is relevant, or vice versa. The Shannon entropy of the
consonant pairs in the Aspell word-list for the Croatian language
is 7.839 bits per consonant pair, but the collision entropy is
5.992 bits per consonant pair. That might seem like a relatively
small difference, but in reality, it's a huge difference, because
we are talking about the logarithmic scale. 7.839 is log2(229) and 5.992 is log2(64). Plugged into the birthday calculations, that's the
difference in p-value of more than an order of magnitude.
And another important thing is that it's important not to
assume that the pairs of consonants (not necessarily separated
by a vowel) at the beginning of a word are strongly correlated
with the pairs of consonants in the middle or at the end of the
words. That's not true, and for languages such as English or
Croatian, which allow for many consonant clusters at the
beginning or at the end of the words, that's especially not
true. I know that seems to be what the basic information theory
(Markov Chain) is predicting, but that's not true. Consonant
clusters at the beginning and at the end of words are governed
to a large extent by the Law of Sonority, and it is saying,
among other things, that consonant clusters which are likely in
the beginning of the words are unlikely at the end of the words.
Here is what it looks like if you plot the graph with the number
of words starting with some consonant pair and the number of
words ending with that same consonant pair in the Hawaiian
language (which has no consonant clusters, each consonant is
followed by a vowel):
The correlation between consonant pairs at the beginning of
words and the end of words in the Hawaiian language is 0.43633.
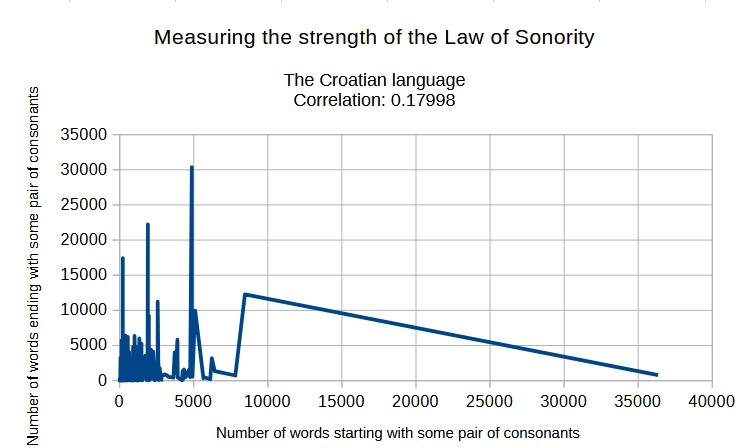
See, the correlation is not approaching 1. And for the Croatian
language, which has many consonant clusters allowed in the
beginning or the end of a word, they are even less correlated,
as predicted by the Law of Sonority:
The correlation between consonant pairs at the beginning of
words and the end of words in the Croatian language is 0.17998.
It seems to me that, in the Croatian language, consonant pairs
in the beginnings and ends of words have a lower collision
entropy than consonant pairs in the middle of words by around
0.9 bits per consonant pair.
I believe I've thus far made three breakthroughs in my life. Back
in 2016, when my mother was in jail, I tried to kill myself three
times. Two times with a belt, and third time by taking alcohol and
paracetamol together. Then I had a weird dream. A character in
that dream told me that Issa, the ancient name for the town of
Vis, was named after the spring that the thermae there were
getting their water from, and that it means "health-giving
spring". When I woke up, I started to research that. Very
soon, I found out that,
according to Branimir Gabričević
(page 28), the thermae were indeed getting their water from a
spring on the western side of them. And I found out that the
ancient name for Varaždinske Toplice, another place with
health-giving springs, was Iasa, and I also found out that the
ancient name for Daruvar, another place with health-giving
springs, was Balissa. That convinced me that the character from my
dream was telling the truth. And I continued studying toponyms,
only rarely thinking about suicide. Then, after I had been
studying toponyms for years and informatics for almost a decade
(including having studied information theory at the university),
an ingenious idea occurred to me: "That is all interconnected. The patterns in toponyms, such as
that k-r pattern in the Croatian river names, have p-values.
Those p-values can be calculated using the Collision Entropy and
Birthday Paradox.". So I wrote the programs to do the collision entropy
measurements and Monte Carlo numerical simulations to estimate the
p-values using those measurements, and I wrote that text
"Etimologija Karašica", which I am very proud of.
And the third breakthrough that occurred to me is the day I
realized what the proponents of mainstream linguistics actually
believe, and what I have to fight against. They mostly believe
that some methodology which assumes that etymologies from
languages we know a lot about are preferable over etymologies from
languages we know little about is a good methodology, and that we
don't need mathematics to study toponyms. In other words, that,
for some reason, etymologies from languages we know a lot about
are more probable than etymologies from languages we know little
about. And now every time I think about ending my own life, I tell
to myself: "Everett-Wheeler Telephones don't exist, or at least they
haven't been invented yet. If you move to some parallel universe
by ending your life in this universe, you will lose the text
Etimologija Karašica. In most universes you exist in, you
haven't come up with that idea to write that text, and you
cannot transmit that information to yourself in another
universe.".
Translating poetry
I've tried translating some poetry from English to Croatian and
vice versa. The ones I think I did the best job at translating are
the Eric Bogle's The Gift of Years
(in case you cannot open it, try downloading
this MP4 file
and opening it in VLC Media Player or something similar) and
Zdenko Runjić'es Galeb i ja
(MP4).
I really like the anti-war poetry about World War 1 (like the Eric
Bogle's The Gift of Years) because I think that now everybody
would agree that World War 1 was in vain. It was supposed to be
the war that ended all wars. How could politicians all over the
world buy into the idea that you could end all wars by putting the
world into one bloody war? I can see how people in Germany might
think that, if they win World War 1, the world would be more
peaceful because the colonies would be distributed among nations
more equally. But I fail to see how could people all over the
world buy into the idea of a war to end wars.
If you are going to translate poetry, take this bit of advice from
me: Don't translate anti-police songs. Translating anti-war songs
about World War 1 is fine, but once you start translating
anti-police songs, somebody will get offended and threaten you
with a lawsuit.
Reviving Latin
I am a bit into the idea of attempting to revive the Latin
language. I have published a few YouTube videos in Latin about
modern topics, such as
this video about gun control in Latin. If you cannot open it, try downloading
this MP4 file
and opening it in VLC or something similar. So, yeah, I am not
impressed by people who are using many Latin and Greek words while
speaking English. I can make an entire video using only Latin and
Greek words. Well, almost. I had to use the English word
telescoping in my video, but I explained what it meant in
Latin. (Telescoping is a phenomenon from social psychology that people
tend to remember distant events as if they occurred recently. It
is related to gun control because many social scientists think
that Gary-Kleck-like studies, that try to estimate how often
guns are being used defensively, suffer from massive
telescoping. That's, in my opinion, unlikely.)
On 16/05/2025, I published an even longer video in Latin, namely,
my video about Croatian river names in Latin. In case you cannot open it, try
downloading it from GitHub
and opening it in VLC or something similar. Let's see if this will
provoke the proponents of mainstream linguistics to discuss
Croatian names of places on YouTube.
Libertarianism
I am also interested in libertarian politics. Government-backed-up
pseudopsychology suggesting that my father raped some little girl
and that I was a witness put my mother and almost my father into
jail. I think that the government power should be limited to
solving simple problems such as the problem of superbacteria
caused by the egg industry (around 70% of antibiotics these days
are used in the egg industry, so it's obvious that what the
government should do about superbacteria is to regulate the hell
out of the egg industry) or the problem of ISPs incorrectly
setting up their DNS servers so that they can be used to massively
amplify denial-of-service attacks. I think it's not the
government's job to attempt to address complicated problems such
as violent crime, global warming, or a pandemic that's currently
going on. Maybe one day the social sciences will advance to such a
degree that they can be trusted to tell the government what it
should do. But since that day is not today, the government power
should be as limited as possible. Anything the today's government
can do about complicated problems is almost guaranteed to be
counter-productive, for the same reason the medieval medicine was
just as likely to hurt its patients as to help them. Any idea we
can come up with about dealing with complicated societal problems
such as global warming, pandemic that's currently going on, or
violent crime, is bound to be as dumb as a rock.
Good policies take away very little freedom while giving us a lot
of safety. For example, the government regulation of antibiotics
in the egg industry takes basically no freedom from an average
person (people who don't have lots of chickens), but it gives them
a lot of safety (drastically reducing the chance of a
superbacteria pandemic). Bad policies, such as lockdowns or mask
mandates, take away a lot of our freedom, while giving us very
little, if any (The main evidence we have that they have any
benefits at all are the results of computer simulations, which
have low evidentiary value.), safety. Good Internet policies such
as requiring ISPs that, if they set up an unencrypted DNS server,
they make it respond only to requests from the IP addresses it is
supposed to serve, take away very little of our freedom (in fact,
none at all from people not running ISPs) while giving us a lot of
safety from hackers who want to implement large-scale
denial-of-service attacks. Bad Internet policies, such as banning
too strong encryption (which is basically what the PATRIOT Act is
about), take away a lot of our freedom, and probably hurt our
safety more than they help it (because, if the government can read
our e-mails, so can the hackers).
Michael Huemer, one of the most prominent philosophers of
modern-day libertarianism (more specifically, anarcho-capitalism),
made up that rhetoric that the government is most of the time in
the position of medieval physicians. I agree with that. However,
he seems to be taking for granted that laws such as laws against
murder are necessary, and that good laws can be enforced by
private security companies in anarcho-capitalism. I think this is
disconnected from the reality. I don't think there is anything a
government can usefully do against violent crime. It's not at all
obvious to me that punishing murderers and similar post-hoc
actions help. But it seems obvious to me that the laws regulating
the use of antibiotics in the egg industry are necessary, and it's
not at all obvious to me how such laws might be effectively
enforced in anarcho-capitalism. In other words, I think we are not
in the position of medieval physicians when trying to address
simple problems such as superbacteria or open DNS servers, but
that we are in the position of medieval physicians when trying to
address violent crime and similar things people usually think of
when they hear the word "politics". That's why I would
define statism as "The belief that the government should make wild guesses based
on questionable premises about how to deal with complicated
societal problems (including, but not limited to, violent crime)
and force those guesses upon ordinary people as a policy.". And by "questionable premises" I primarily mean
social sciences.
The unfortunate thing about social sciences that I think most
people don't understand is this: In natural sciences, in order to
discredit an experiment, you usually need to find a flaw with the
experimental setup, whereas, in social sciences, you can usually
discredit an experiment by saying "Well, perhaps a better mathematical model would suggest the
findings are not actually statistically significant.". To understand what I mean, consider the k-r pattern in
the Croatian river names. You can point it out to the proponents
of mainstream linguistics, and they will say: "You've fallen victim to the Birthday Paradox. The probability
of such a pattern occurring by chance isn't low at all.". Then you can point out them the fact that a simple
birthday calculation, which assumes that the Croatian language has
20*20=400 equally likely consonant pairs, suggests that the
probability of such a pattern occurring by chance is around
1/10'000. Then the proponents of mainstream linguistics will say:
"You need to take into account the fact that some consonants are
more common than others.". Then you can point them out that the collision entropy of
a consonant in the Croatian Aspell word-list is around log2(14), and that a birthday calculation that takes that fact into
account suggests that the p-value of that k-r pattern occurring by
chance is around 1/500. Then the proponents of mainstream
linguistics respond by saying: "Well, some pairs of consonants are more common than
others, due to the phonotactic constrains. You need to take that
into account.". Then you can study information theory and attempt to
measure the collision entropy of different parts of the grammar of
the Croatian language (including phonotactics), and show them
complicated calculations that suggest the probability of that k-r
pattern occurring by chance is somewhere between 1/300 and 1/17.
Then they will complain that those calculations are probably
incorrect because they are relatively complicated and have not
been peer-reviewed. Then you publish those calculations in two
peer-reviewed journals and ask a few experts in the information
theory to check your math, which is enough to make some (but not
nearly all) proponents of mainstream linguistics shut up with the
comments about how your calculations are probably wrong. Then the
proponents of mainstream linguistics will say stuff like: "What if different word classes in Croatian have a significantly
different collision entropy? What if nouns have a significantly
lower collision entropy than the rest of the words in the Aspell
word-list? River names are nouns.". I think you get the point by now: you can usually
discredit an experiment in social sciences by making an ad-hoc
hypothesis that a more appropriate mathematical model would
suggest the findings are not actually statistically significant.
And, in theory, we can probably keep going like that forever, or,
in praxis, we can go like that until the calculations of the
p-value become so complicated that nobody can review them. I see
no point in attempting to make a more complicated calculation
suggesting that this k-r pattern is indeed statistically
significant: if what I've done by now is not enough to convince
the proponents of mainstream linguistics, probably nothing would
be. Proponents of mainstream linguistics complain both that my
calculations supposedly don't reflect how real languages behave
(and I see no reason to think that nouns actually have a
significantly lower collision entropy than the rest of the words)
and that my calculations are so complicated that they are hard to
review. The absurdity here should be apparent: a calculation that
takes into account how languages really behave (if nouns really
have a lower collision entropy than the rest of the words) would
be even more difficult to review than my calculation is. The
solution proposed by the advocates of mainstream linguistics is
often to use what they call traditional methods, but the problem
with that is that those traditional methods not only don't appear
to be based on mathematically sound principles, they also appear
to go precisely against them (they give results that information
theory says are improbable, such as that the k-r pattern is a
coincidence). What is then the point of trusting social scientists
to tell us how the government should operate? If most of the
experiments in social sciences can be discredited with saying
"Perhaps a better statistical model would suggest the results
are not actually statistically significant.", I see no reason to trust what social scientists have to
say about politics.
As a former anarchist, I've made
a YouTube video about how to convincingly argue against
anarchism. If you want to watch it, but your browser cannot stream MP4
videos, try downloading
this MP4 file
and opening it in VLC or something similar. Though, in my
experience, most of the people on the Internet who use the word
anarchist to describe themselves are not anarchist or even
libertarian. Many people who call themselves anarchist hold
anti-vaxxer beliefs. And by anti-vaxxer I don't mean being
against forced vaccinations, I mean actually believing that
vaccines somehow magically cause all kinds of diseases. That's
blatantly incompatible with anarchism. What makes them think
vaccines would be tested more in an anarchy? It seems obvious to
me that, in an anarchy, we would have vaccines for a new disease
sooner, but those vaccines would be less tested. The reason
vaccines are tested so much today (that it took almost a year
between the first prototype of the RNA vaccine against COVID and
its release to the public) is because of the government regulation
passed soon after the Cutter Vaccine Incident in the 1950s (when a
vaccine which was supposed to protect people from polio turned out
to be spreading the disease). So, yeah, it's possible that my
video will not convince an anarchist you are debating with
precisely because they are not actually anarchist.
I think the main reason people fall into this trap of anarchism is
the fact that most of the people, when asked to argue for the
existence of the government, respond with some Hobbesian nonsense
about bellum omnium contra omnes, that is, the
idea that the government has a huge positive effect on violent
crime. That idea is, of course, blatantly incompatible with modern
social sciences. So it is easy to make the wrong conclusion that
there are no good arguments for the existence of the government.
There are good arguments for the existence of the government, it's
just that people tend not to understand those good arguments.
Another reason why people fall into this trap of anarchism is that
anarchist ideas seem appealing because they make world problems
seem like they are self-solving. A good example of that is the
problem of superbacteria. Anarchists, when asked what their take
on superbacteria is, respond with something like: "Well, the problem of superbacteria is largely caused by the
governments removing the incentive for scientists to discover
new classes of antibiotics via intellectual property laws. And
even so, the lab-grown meat will soon make the problem far less
severe, since around 80% of antibiotics these days are given to
farm animals. And you can do your part now by going
vegetarian.". That sounds so appealing, people want to believe that so
much that they will not do research (such as looking up the
statistics on where exactly antibiotics used in agriculture go...)
to realize that's nonsense. There are a number of problems with
that response. Number one, there is no reason to think there even
are useful antibiotics left for scientists to discover. The fact
that we've found dozens of chemical compounds that kill
prokaryotes but not eukaryotes is already amazing, we cannot
expect that there are more. The second problem with the anarchist
take on superbacteria is that lab-grown meat won't address the
problem of superbacteria because almost all antibiotics used in
agriculture these days are being used in the egg industry, and we
won't have lab-grown eggs any time soon. We struggle to produce
muscle meat in laboratories, and eggs are far more complicated
than muscles. And for the exact same reason, many people going
vegetarian (unless by "vegetarian" they mean
abstaining from eggs, and I seriously doubt they do) would do
nothing to address the problem. Government regulation of the egg
industry addresses the problem. But to a layman, the anarchist
response will probably sound very appealing.
I've read some anarchists claiming that the statistics
suggesting that most antibiotics are being used in the egg
industry are wildly inaccurate, and that around 80% of
antibiotics goes to cows and pigs. I am quite sure that
statement is inaccurate because, well, you need to consider that
around 45% of antibiotics used in agriculture are ionophores,
which are antibiotics that are effective in birds but not in
mammals. I've asked
a Quora question about that.
Similarly with global warming. When anarchists are asked about
their take on global warming, many of them will respond by showing
some dubious analyzes arguing that methane is responsible for more
global warming than CO2. Curiously, those analyses never take into account the fact that
the spectres of water and methane are similar. CO2
causes global warming because it absorbs many frequencies that
water in the atmosphere doesn't, but that's not quite true for
methane. And after they have tricked you into thinking methane is
a more important greenhouse gas than CO2, they will show you some statistics that supposedly show that
our methane emissions reached their peak in the 1980s and have
been decreasing ever since. Those statistics are simply wrong
analyses of the data, and I have made
a YouTube video explaining why. If you cannot open it, try downloading
this MP4 file. I shall warn you, it is pretty technical. In case it helps (if
you speak Croatian well, but not English so well),
here is a text in Croatian explaining that (in even more
details). Long story short, I think those statistical analyses are
implicitly assuming that methane in the atmosphere is an IT1-type system with respect to our methane emissions, which it
isn't. So, yes, anarchists are making it look like global warming
is a self-solving problem, which it isn't. Though, unlike
superbacteria, it is not obvious how a government might address
the problem of global warming without doing a ton of collateral
damage.
I've tried to discuss that (my finding that those statistical
analyses are flawed because of cybernetics) on a few Internet
forums, but, honestly, the responses I got are so moronic that I
am left without words. Two people were
comparing my claims to Flat-Earthism
("but you trying to data crunch it away or find any kind of
answer in mathematics is very much like your weird atmospheric
refraction theories in flat-Earthism"). Like, attempting to do a proper statistical analysis
using university mathematics is somehow the equivalent of
rejecting all quantitative methods in natural sciences (Which is
what Flat-Earthism essentially is, as anybody who values
quantitative methods realizes that the Round-Earth explanation
for ships disappearing bottom first is better than the
Flat-Earth one.)? If anything, it is precisely the opposite,
right? And one person appeared to be unable to understand grade
12 mathematics (what a derivative is). I don't know what the corect response is in that situation.
In any case, I think it's my duty to correct misinformation,
especially since it was me who was spreading it a few years ago.
But if people are unwilling to accept the truth or are perhaps
even unable to understand it... I don't know what to do. And, in
all seriousness though, that argument can be paraphrased as
"Look, the reality can be harsh, but the reason the Earth is
not boiling from methane in the atmosphere is because we are
torturing cows in factory farms instead of letting them eat
grass.". If that statement doesn't trigger your BS detectors,
then I don't know what will.
It doesn't take a lot of imagination or knowledge of facts to see
the bad effects of government overreach. Seeing what would happen
in an anarchy is a lot more difficult. It doesn't take much
knowledge of facts or much imagination to see that
institutionalized pseudopsychology suggesting that my father raped
some little girl and that I was a witness put my mother and almost
my father into jail, and to suppose that wouldn't have happened in
an anarchy. It doesn't take much knowledge of facts and it takes
only a tiny bit of imagination to understand that free colleges
lead to people becoming dependent on colleges (credentialism),
which cost many students their mental health. Like I got psychosis
when studying computer engineering, and I still need to take
Risperidone, Biperiden, and Alprazolam. However, it does take
quite a bit of knowledge of facts and a quite a bit of imagination
to realize what bad things would happen in an anarchy. A pandemic
of superbacteria, Internet being paralyzed by denial-of-service
attacks made possible by many ISPs incorrectly setting up their
DNS servers... That's one of the reasons people become anarchists.
Many libertarians (and some conservatives) believe that the reason
socialism does not work is what they call
Economic Calculation Problem, which basically says that
optimal prices of goods and services can only be approximated in a
decentralized manner. I don't think that is true, in fact, I think
that statement contradicts much of informatics. Isn't it the
equivalent of saying that prices can only be determined by an
algorithm which can be implemented in a multi-threaded way, but
cannot be implemented in a single-threaded way? It seems obvious
to me that there cannot be such an algorithm. Furthermore, it also
seems to contradict one of the basic facts from the Computer
Networks classes, and that is that a large decentralized wireless
network cannot exist. Large decentralized wireless networks cannot
exist due to what's called Problem of Hidden Terminal. It's
when a computer can see some computers in a wireless network, but
cannot see all of them (because some of them are behind a barrier
or simply too far away). And thus it can approximately-correctly
estimate the amount of traffic that's going through a network, but
it underestimates the number of computers that are available to
handle network requests. It will refuse to send network requests
under the mistaken belief that the network is overloaded. There
doesn't seem to be any algorithm the computers in a large
decentralized wireless network may follow to avoid that problem.
That's why centralized wireless networks are far more efficient
than decentralized wireless networks. I have not seen any
proponent of the Economic Calculation Problem respond to those
objections.
Many people, including perhaps most libertarians, think that
democracy incentivizes the governments to solve problems. That
democracy is the best system of government because democratic
governments address problems which people are aware of and are
willing to vote for them to get solved, whereas other forms of
government don't even do that. I don't think that's true. I think
the right response to that statement is: "Don't think, look!". Looking at what governments are good at, I think
governments excell at solving problems common people tend to
understand poorly, if at all. Just about any government around the
world has laws regulating the use of antibiotics in the egg
industry (which is why we haven't yet had a pandemic of
superbacteria), even though an average person has little or no
understanding of the problem of superbacteria. Just about any
government around the world has laws against open DNS servers
(which is why the Internet isn't paralyzed by denial-of-service
attacks), even though an average person doesn't understand how the
Internet works well enough to understand why those laws are
necessary. To me it seems plausible, if not probable, that
governments are solving problems in spite of democracy, rather
than because of democracy.
Some libertarians even go a step further by saying that capitalism
doesn't need a government because capitalism allows us to address
global problems by being conscientious customers. Which is true in
theory. Capitalism, in theory, does allow us to address many
global problems via collective action by many people being
conscientious customers, certainly much more so than communism
does. But I don't think this works in praxis. Once again, I say:
"Don't think, look!". Most of the people who try
to be conscientious customers do ineffective or even
counter-productive things in an attempt to address global
problems. For example, many people who are worried about the
working conditions in the developing world respond by boycotting
sweatshops. But it's hard to see how boycotting sweatshops might
do anything but make the problem worse. People are in sweatshops
because they believe the alternatives are even worse, and they are
probably right about that (They certainly have more insight into
the situation in their country than we do.). Many people,
including me not long ago, are worried about superbacteria, so
they stop eating meat (or, worse yet, only stop eating red
meat)... but they continue eating eggs from factory farms. That's
not helping a lot since most of the antibiotics these days are
being used in the egg industry (so much so that 45% of antibiotics
used today are ionophores, which are antibiotics effective in
birds but not in mammals). Many people, including me not long ago,
are worried about global warming, so they stop drinking milk... to
replace it with the cheapest of the plant-based milks that is rice
milk. That's not helping, since the production of rice also emits
a lot of methane. Switching to oat milk does help a bit, but oat
milk is more expensive, and people tend to think there are some
easy and cheap solutions to global problems. That's why I think a
government is necessary to address global problems: because when
many people (politicians) are debating on how to address global
problems, they are a lot less likely to be wrong than an
individual who is making uneducated guesses is likely to be wrong.
Furthermore, it's not obvious how the problems such as open DNS
servers could be solved in anarchy even in a phantasy land where
everybody is putting effort to be well-informed about global
problems. People giving up eggs won't lead to a catastrophy, but
people giving up the Internet would lead to the economy performing
very badly.
One of the things I, as an engineer, hate the most when discussing
politics is that many people seem to dismiss huge engineering
challenges in implementing their political proposals. Don't say
that we should power our national grid with solar power and wind
power, when they are both highly unreliable (storing large amounts
of electricity is a huge chemical engineering problem), and merely
connecting solar power to the national grid is an electrical and
electronical engineering nightmare (because solar pannels produce
direct current with constant current, rather than alternating
current with constant voltage like other power sources). Don't
talk about using the Internet in an anarchy, when making the
Internet work in an anarchy would be a huge computer engineering
challenge, if possible at all (due to the problems such as the
problem of improperly configured DNS servers, and such problems
will be even more severe in the near future due to the improperly
configured HTTP 3 and other QUIC servers). Don't suggest tackling
the problem of superbacteria with lab-grown animal products, when
making a lab-grown egg is an absolutely huge engineering challenge
(and most of the antibiotics these days are used in the egg
industry). I've written
a blog-post about that.
I concede it is not at all obvious how libertarianism might be
achieved. How we might get from a society we are currently living
in to a libertarian society? Currently, we are all bound
(especially if we try to start our own business) by tens if not
hundreds of thousands of pages of laws. It's obvious that most of
those laws are either unnecessary or are even harmful. But what's
also obvious to me now (although it wasn't obvious to me for a
very long time) is that an average person is not capable of
telling which laws are necessary. An average person in today's
society has almost inverted BS detectors when it comes to laws. An
average person today believes in the Hobbesian nonsense of
"bellum omnium contra omnes", so it
seems to them that laws against murder are necessary. A little bit
of thinking makes it seem at least probable that the laws against
murder are unnecessary, but hardly anybody is rational enough to
realize that. As well, an average person doesn't understand the
problem of superbacteria well enough to understand why laws
against the overuse of antibiotics in the egg industry are
necessary. And an average person doesn't understand how the
Internet works well enough to understand why laws against open DNS
servers and against misconfigured QUIC servers are necessary.
Politicians cannot be expected to be a lot better than an average
person when it comes to this. That's why the congress voting on
each legislation whether it's necessary is unlikely to work: it's
quite possible we will lose necessary laws (laws dealing with
superbacteria or open DNS servers), while keeping many harmful
laws (such as, well, the laws against murder). I've written
a short story in Croatian illustrating that point. As barbaric as this may sound, I think that a good partial
solution is to arm the civilians to make the government afraid of
passing too restrictive laws. I think that works in the vast
majority of situations. That is, outside of some paradoxical
situations such as the Four Pests Campaign (If more civilians had
been armed during the Four Pests Campaign, probably more sparrow
birds would end up being killed, and the invasion of grasshoppers
would be worse, leading to more people dying in the Great Chinese
Famine.). Finding out which laws are actually necessary requires a
rational discussion about politics, and most people are not
willing to have it.
Vegetarianism
I am also a vegetarian and I like doing vegegelicism on Internet
forums. Once you accept some libertarian philosophy (or probably
any form of liberalism), there seems to be no particular reason
not to extend it to non-human animals. While I don't know what's
the best way to do vegegelicism, I know very well what one
shouldn't do. I've written
a long blog-post about vegegelicism.
One important thing which is, for a reason that escapes me,
usually left unsaid when it comes to things related to
vegetarianism, veganism, and similar things, is that the vast
majority of antibiotics used in agriculture go to the egg
industry. That means that, if you stop eating meat, but you
continue buying eggs from factory farms (like I was doing for
almost a decade), you are probably not really helping public
health (You are certainly not helping against superbacteria
then.). I am not sure whether avoiding pork is a sensible way of
attempting to postpone the inevitable flu pandemic, and I've asked
a StackExchange question about that.
One important thing about debating which I've learned only after
almost a decade of debating various things on Internet forums (not
limited to vegegelicism) is not to use not-even-wrong arguments.
Understanding it will immediately make you multiple times wiser. A
significant proportion of arguments used on Internet forums are
not only not right, they are also not even wrong. And while it is
difficult to tell apart a right argument from a wrong one, it is
not all that difficult to tell apart an argument that is not even
wrong. Simply, before using some observation as an argument
against mainstream science, ask yourself how your theory (I am
using that word in the informal sense here) explains that
observation. And if you cannot give a sane response to that
question, then don't use that argument. For example, in the
debates about Flat-Earthism, the argument "If the Sun is 150'000'000 kilometers away from the Earth, how
it is that, when the Sun is shining through clouds, the sunbeams
do not appear parallel?" is a way better argument than the argument "If the horizon is caused by the Earth being round, why it is
that the horizon appears to rise with us as we climb?", even though neither of them are right. Flat-Earth Theory
can indeed explain away the sunrays appearing to converge by
asserting that the Sun is 5'000 kilometers up in the sky, but
nobody who is being honest with himself will say that the
Flat-Earth Theory (the Earth being flat and there being magical
curvings of light) easily explains the horizon appearing to rise
with us as we climb (What even is the horizon then?). I've written
a blog-post about that.
I also think that looking for not-even-wrong arguments is the most
effective way of detecting pseudoscience, much better than looking
for ad-hoc hypotheses is. Although pseudosciences are based on
ad-hoc hypotheses, and ad-hoc hypotheses are a smoking gun of
pseudoscience, I don't think an average person is capable of
telling apart even the most blatant ad-hoc hypotheses. For
instance, back when I was a Flat-Earther, I didn't realize that
"Ships disappearing bottom first is an illusion caused by
waves." is a blatant ad-hoc hypothesis. Until I started doing
mathematics, I didn't realize that the waves would need to be
higher than your eye-level for that to happen. Or most of the
people I know, even the most intelligent ones, tend not to
immediately realize why
the first argument I got when presenting my argument in the
text "Etimologija Karašica" on an
Internet forum
is an absurd thing to say. But, even when I was a Flat-Earther, I
understood very well that Flat-Earthers tend to make arguments
such as "The horizon appears to rise with the observer as he climbs.", using phaenomena as arguments against mainstream science
for which it's not at all obvious how the alternative theory
explains them. I just didn't understand that's called
not-even-wrong argument and that it is a smoking gun of
pseudoscience, just as much as ad-hoc hypotheses are. I think a
layman can easily tell apart not-even-wrong arguments, much more
easily than to tell apart ad-hoc hypotheses.